

At the beginning of 2021, Namex IXP has started the rollout of its next-generation peering platform, the active infrastructure which is at the core of its network interconnection facility. This new platform relies on an IP fabric design with VXLAN as the overlay network and BGP EVPN as the control plane protocol. The development of this project started back in March 2020 and saw Mellanox and Cumulus Networks (both parts of NVIDIA corporation now) as major technological partners.
Before diving into the details, a brief historical note may help to understand the drivers and motivations behind such technical choices.
Managing scale and complexity: the evolution of a peering platform
Having been part of Namex technical staff for nearly 20 years, I had the pleasure and honour to take part in the development of several generations of its main peering platform. What follows is a quick account of how this evolution took place and the reasons behind it. Beware: it is Namex own evolution, it is not supposed to be generally valid for any Internet Exchange in the universe, but it may probably reflect the experience of several other IXPs that evolved from a small core to a larger, medium-sized, customer base.
In its most elementary form, a peering platform is an infrastructure that provides layer-2 connectivity between edge customers’ routers, in a simpler form: it is a switch with VLANs!
The key featuress that determine the establishment of technology for a peering platform can be summarized in:
- Port density: the total number of network ports (switch ports) that can be allocated to customers
- Port technology: the type (i.e. speed and media) of ports that can be allocated to customers
- Switching capacity: the overall network capacity that the platform can support
- Fault-tolerance: the ability of the platform to provide service continuity even when some of its parts are failing, this implies a certain level of redundancy of both hardware and software components
- Manageability: the easiness of use, configuration, and troubleshooting of the platform as a whole
The factors that drive its evolution are mostly two and intertwined: the scale and the management of associated complexity. We’ll see this in more detail in a while.
Origins: the monoliths
In the beginning, there were big and bulky switches …
Back in the early 2000s, switch choices were mostly obligated. There was just one design that could address all the key factors and it was the monolithic modular switch composed of a chassis supporting power distribution and data backplane and several line cards to address connectivity needs.

When I first arrived at Namex, the peering platform consisted of a couple of Cabletron SSR-8000 switches, equipped mostly with FastEthernet line cards and some GigabitEthernet (fiber) cards. Port density was limited but fit the size of the customer base. Fault-tolerance and redundancy were achieved mostly by having two devices supporting two logically and physically separated peering LANs, customers could choose to connect to one or both LANs with different IP addresses. It was basically a double star network topology with no need to manage switch interconnection and related loop complexities.
As the customer base grew, natural choice was to replace each device with a bigger one, in this case choice fell on an Enterasys Matrix N7 and a Cisco Catalyst 6509-E which both added 10 Gigabit Ethernet connectivity to the game in a limited fashion.
In about 5-6 years, this architecture clearly showed its limits. Growth in scale could only be accomodated by resorting to bigger and bulkier switches, this also had some side effects such as the concentration of all network connections into two hot spots, while the datacenter was growing and customer equipments were spread all around a larger space.
The first workaround came in the form of a third switch (actually, a Cisco Catalyst 6506-E) that was added to the existing couple to expand port density. This introduced the need for inter-switch connections and consequent additional complexity management, a major shift in perspective that eventually led to second-generation platforms.
Second generation: the switching fabrics
An army of tiny, highly coordinated switches …
Back in 2012-2013, as customer base and datacenter spaces were constantly growing, a technology leap was inevitable. Previous experience showed that scale could be managed by adding devices and not by enlarging the existing ones. Indeed at that time, driven by datacenter and virtualization growth, vendors had started to propose switch models that were smaller in size and higher in port density and type. But adding switches also introduced a burden in network complexity, in the quest for a network topology that was both fault-tolerant and loop-free.
Luckily at that time, vendors were also introducing several technologies which fell into the category of so-called switching fabrics: these mechanisms enabled switches to be interconnected by multiple paths without the need to directly manage loop-avoidance protocols such as STP.
The choice fell on Brocade (now acquired by Extreme Networks) with its Virtual Cluster Switching technology, supported by TRILL protocol, which equipped the VDX switches series. This technology enabled us to design a network that was composed of six nodes, interconnected by a full mesh of 2x10G links. Nodes included a couple of Brocade VDX-8770 (a smaller, compact form of modular chassis switch) and four Brocade VDX-6740, a lightweight top-of-rack switch. All topology (loops!) and traffic balancing issues were automagically taken care of by the inherent TRILL protocol and the overall platform could be managed as a single logical switch.
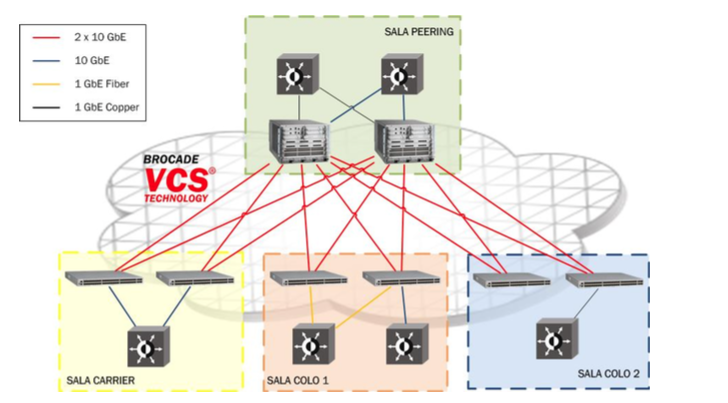
The original design proposal by Brocade for Namex second generation platform
The introduction of a switching fabric was a major breakthrough in the evolution of Namex peering platforms, it introduced several key concepts that were drivers for future developments:
- Managing scale by growing in the number of nodes
- Offloading complexity to a transparent control protocol
- Introducing a liminal form of leaf-spine architecture (actually, an impure one in this case)
- Breaking down footprints and power consumption (and costs …) with smaller and more efficient devices
All in all, Brocade VCS proved to be an effective solution and also a resilient and stable one, and yes it has worked flawlessly so far (as it is still in production until the full deployment of the new platform). Its inherent limits became to appear with the need for 100Gbps as the VDX platform had limited support for 100GigabitEthernet in the form of 4-ports line cards with legacy CFP2 ports, uniquely on the 8770 chassis.
This led us to the latest leap, towards next-generation platforms …
Next generation: introducing IP fabrics
Good old IP and BGP to the rescue …
Switching fabrics paved the way to a different approach in the design of large layer-2 interconnection platforms, but at the same time switching fabrics technologies were progressively abandoned by vendors, in favor of IP fabrics and overlay networks. Around 2017/2018, as the need for 100 Gigabit Ethernet connectivity became more impending, a new evolutionary step was needed.
Guidelines for the design of a new platform were mostly matured from previous experience:
- Scalability through the addition of nodes paired with a pure leaf-spine architecture
- A mostly transparent control protocol
- Support of higher bandwidths (40G/100G) and port densities
Also, additional requirements emerged as the peering platform began to evolve not only as a public peering interconnection infrastructure but also as a platform to support private customer-to-customer interconnections in the scenario of an open marketplace in which any network operator is able to buy and sell services on top of an L2 interconnection facility. The need for improved manageability in the provisioning of such on-demand interconnection services, paired with the complexity of an infrastructure comprising tenths of independent nodes to be orchestrated as a coherent whole pushed for additional requirements in terms of configuration frameworks and network automation in general.
Moreover, in an effort to design a real future-proof architecture that could resist (at least in its conceptual foundations) the next 10 years, an eye was kept on full decoupling between hardware platform (nodes) and software control layer (network operating system), this brought the concept of open networking into the game.
All of these factors eventually led to the choice of NVIDIA Mellanox as the hardware vendor together with NVIDIA Cumulus Linux as the network OS, paired with an entirely in-source developed configuration framework based on Ansible.
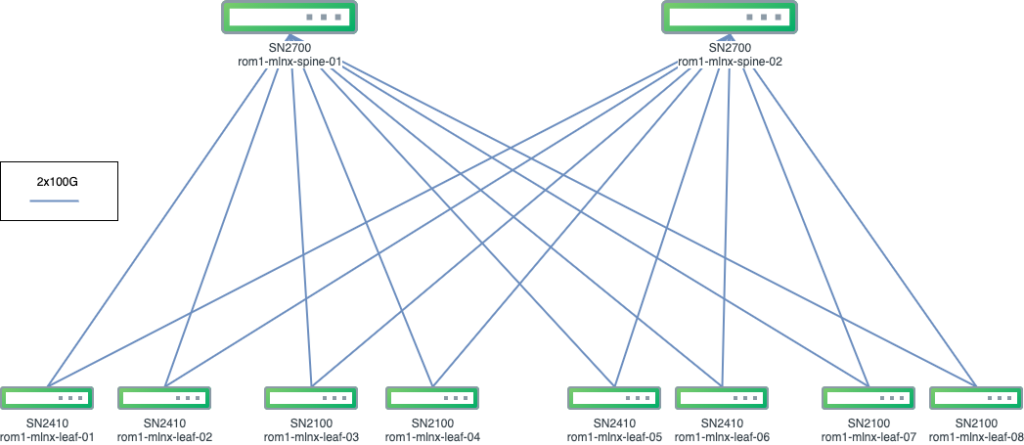
The platform consists of 2 Mellanox SN2700 (32x 100G ports) spine nodes with 4 Mellanox SN2100 (16x 100G ports) and 4 Mellanox SN2410 (48x 10G ports + 8x 100G ports) leaf nodes. Each leaf node is connected with 2x100G links to any spine node, thus achieving a backplane of 400G output from any leaf node.
The basic features of the IP fabric implementation based on VXLAN and BGP/EVPN are the following:
- All nodes properly act as L3 devices (routers) in the relationships between each other
- Customer traffic is switched locally on the node but routed when flowing between different nodes
- Customer traffic entering a leaf node and destined to a remote leaf node is encapsulated into UDP packets and then routed between nodes
- Tunnels are established between any leaf nodes which provide encapsulation and L3 forwarding of L2 frames
- BGP is used to exchange information about MAC address reachability between nodes, by means of an additional ‘evpn’ address family
- BGP ECMP (Equal Cost Multipath) is used to balance traffic load across multiple paths between leaf nodes
In short, the use of IP as the underlying “fabric” protocol, paired with BGP for dynamically controlling the data paths, ensures stability and simplicity of use, thus finally overcoming the complexity issues of meshed L2 networks. We’ll see more technical details about this in the next sections.
Design and implementation of Namex next-generation platform
As we have seen, the choice of an IP fabric architecture arose as a natural evolution of trends and experiences accumulated in the past 15 years of operations. In the next sections we will look through the design and implementation phases in more detail, underlining the role and support of vendor(s) in the overall process.
Design and implementation process
It is useful to summarize again some of the main requirements of the project:
- Distributed leaf-spine architecture based on VXLAN overlay and BGP/EVPN control plane
- Customer (leaf) connectivity from 1G to 100G
- 100G spine connectivity
- Fully automated management from day one
While there is not much to say about the choice of Mellanox switches, since this was simply the hardware platform that looked more promising in terms of feature set, performances, availability, and choice of models, the real breakthrough was its coupling with Cumulus Linux, which fully exploited the capabilities of such a platform.
In simple terms, Cumulus Linux is a Linux-based operating system for network devices which couples the standard Linux system interface with the underlying hardware equipment, offloading all major network operations to the corresponding ASICs. In short: think of (and manage) your switch as a Linux box with hardware-accelerated network functions.
While this is a game changer for datacenter environments, as one can eventually manage servers and network boxes with the same interface, this introduces some straightforward improvements also in a more traditionally network-oriented scenario such as the one of Internet Exchanges.
On top of this, Cumulus Linux is specifically designed for datacenter applications and it is strongly oriented at the implementation of VXLAN/EVPN based IP fabrics. This translates into a myriad of minor details that make the life of the network architect really easy: the overall configuration and setup of the basic fabric architecture is really a matter of few lines of configuration on each node. Additionally, Cumulus offers full native support of network automation frameworks such as Ansible, making it possible to fully automate the platform from setup to normal provisioning operations.
Original design included:
- Cumulus Linux 4.2 installed on all switch nodes
- FRR Routing Suite in charge of BGP/EVPN control plane management
- Netfilter (ebtables) for standard MAC ACL support
- Automated deployment from an exernal, Ansible equipped, management server
In the initial implementation phase, Cumulus was kind enough to provide us with a custom simulator in their own virtualized lab environment (CITC, Cumulus In The Cloud), specifically tailored to match our real-life deployment. Based on generic templates provided by Cumulus, we developed our own Ansible deployment framework which took care of:
- Node addressing (loopbacks, tunnel endpoints)
- Cross-link, backplane configuration
- Kernel and switch interface fine tuning
- Monitoring and management protocols configuration (SNMP, sFlow, NTP)
- Foundation VLANs and VXLANs configuration (public peering VLAN, quarantine VLAN, test VLAN)
after deploying the full configuration to the virtual platform in the simulator, we tested basic customer configurations before proceeding with real-life deployment.
On the real, physical platform all nodes were just connected to the management network, took basic configuration with ZTP and then the full fabric setup was performed in a few minutes by Ansible with no errors. After that, we began real-life testing, focusing mostly on filtering configurations which are an essential part of IXPs best practices.
As a last stage in the deployment phase, the new platform was connected to the existing one, thus preparing for customer migrations.
Steps towards full network automation
As we have seen, network automation via Ansible has been a major part in deployment of the platform, and also a necessary one since the complexity of topology and number of nodes could easily lean towards hardly detectable errors in case of a manual, node by node, configuration.
In this perspective, Cumulus Linux proved to be an ideal interface for network automation since:
- It provides native Ansible support (local execution of tasks)
- Network configuration is split into multiple files instead of a monolithic file
- Configuration change is achieved by rewriting and reloading files without the need for complex extraction and parsing of configuration snippets (this proves tremendously effective in all cases where you need to remove a specific configuration section)
These key aspects were leveraged at their best in the next phase of our process towards full network automation: automation of provisioning operations. Choosing the right approach was crucial at this stage, our goal was to develop a framework that could push configurations to the nodes starting from a high level interface such an administration dashboard that might eventually provide customers on-demand service configuration capabilities (example: “configure this VLAN between my router port and that customer router port”). This required the Ansible configuration framework to act as an interface layer between an higher level software system (currently under development) and the actual nodes.
Our first approach was to try and mimic the workings of CLI commands (yes, Cumulus also has its own CLI, named nclu) but this approach implied the same issues you have with traditional network operating systems, basically: you have your device status wired into the device itself.
The breakthrough was to understand that we needed to move the state out of each node and into an external repository, this proved to be most easy and effective way to go, because:
- External repository acts as a proxy between any higher-level software (think of IXP Manager or our own management software under development)
- Configurations can be generated on the fly by Ansible according to data retained in the repository
- Describing the desired final state of the node is actually the proper way Ansible was designed to work
- State repository can be managed as software code through a version management system such as Git
We thus developed our own configuration language inside the Ansible framework which enables us to perform basic provisioning tasks:
- Full customer interface configuration (single port, bond, VLAN behavior)
- Customer VLANs and supporting VNIs configuration
- Basic ACL configuration (MAC and protocol filtering)
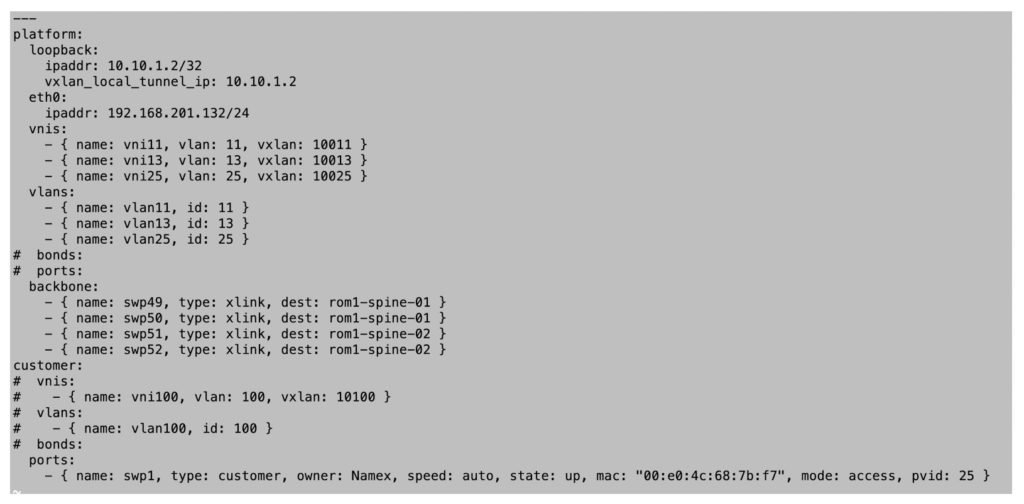
We finally ended in a situation where, since day one, all provisioning operations were automated via Ansible playbooks: this is a good starting point for future integrations with more advanced software systems. While we are still implementing NVIDIA Cumulus Visibility Tool NetQ with its native integration of Telemetry (What Just Happened feature), we limit command line interaction to checks and monitoring.
Moving into production
We started migrating the first customers at the end of December 2020 and we are now in a sufficiently advanced state of production to reflect on lessons learned and draw some conclusions.
Lessons learned
While the IP fabric architecture proved to be extremely stable since its early implementation phases, one of our initial concerns was about hardware compatibility with different vendors. As a peering platform, our switching architecture has to interact with devices from a multitude of vendors, ranging from high-end Cisco and Juniper routers to widespread Mikrotik devices, also including software routers based on Linux or BSD systems. By providing a higher level interface with respect to traditional network operating systems, Cumulus Linux may initially seem to offer lesser support in tweaking low-level hardware parameters. Actually, we were pleased to observe how NVIDIA Mellanox hardware resolved most compatibility issues automatically, without the need for tweaking we were used to in previous platforms. Eventually, the Cumulus Linux interface provides a larger amount of information about the underlying hardware, information that is also easily parsable and collectible.
One of the major area we found differences with traditional networking was in ACL based filtering, which in Cumulus Linux relies on the Netfilter suite. Through careful tweaking of configuration, we were however able to address our most common customer configurations.
We also had some interactions with NVIDIA Global TAC and we were pleased about the level of support offered. Also, our local NVIDIA Italy contacts proactively engaged with us throughout all the phases leading to the successful launch of the platform and we feel that within NVIDIA there is a common understanding of our distinctive scenario of application.
Final thoughts – the path forward
In the end, we think that “switching” to IP fabrics has been both an inevitable and natural way to go, which does not come out of nowhere, but is the result of nearly 20 years of experience in the operations of the exchange peering platform.
IP fabrics now give us the flexibility and robustness to design largely scalable platforms in a modular way and also helped us design a template architecture that we can replicate and deploy at any site with simple, automated operations.
Automation and open networking, empowered by Cumulus Linux, opened up totally new development perspectives, shortening the distance between the world of software systems and the world of network devices. This is probably the major discontinuity and the source of a true forward leap beyond previous architectures.
Looking forward, we see how our world is quickly undertaking yet another revolution: online gaming, entertainment, and CDN-driven online contents such as streamed sports events are set to rapidly transform IXs, with the adoption of 400GE and in a few years 800GE as the peering speeds to support this traffic: we feel that we are now prepared to take on this new challenge.
We are conscious that we are moving through a new territory, and we are confident that this experience will benefit and elevate ourselves, our Technological Partner NVIDIA, and the overall IXP community to new heights.